Quadratic classifier
A quadratic classifier is used in machine learning and statistical classification to separate measurements of two or more classes of objects or events by a quadric surface. It is a more general version of the linear classifier.
Contents |
The classification problem
Statistical classification considers a set of vectors of observations x of an object or event, each of which has a known type y. This set is referred to as the training set. The problem is then to determine for a given new observation vector, what the best class should be. For a quadratic classifier, the correct solution is assumed to be quadratic in the measurements, so y will be decided based on
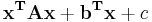
In the special case where each observation consists of two measurements, this means that the surfaces separating the classes will be conic sections (i.e. either a line, a circle or ellipse, a parabola or a hyperbola).
Quadratic discriminant analysis
Quadratic discriminant analysis (QDA) is closely related to linear discriminant analysis (LDA), where it is assumed that the measurements from each class are normally distributed. Unlike LDA however, in QDA there is no assumption that the covariance of each of the classes is identical. When the normality assumption is true, the best possible test for the hypothesis that a given measurement is from a given class is the likelihood ratio test. Suppose there are only two groups, (so 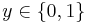 ), and the means of each class are defined to be
), and the means of each class are defined to be 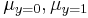 and the covariances are defined as
and the covariances are defined as 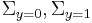 . Then the likelihood ratio will be given by
. Then the likelihood ratio will be given by
- Likelihood ratio =
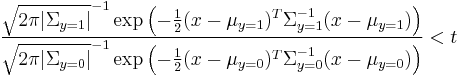
for some threshold t. After some rearrangement, it can be shown that the resulting separating surface between the classes is a quadratic. The sample estimates of the mean vector and variance-covariance matrices will substitute the population quantities in this formula.
Other quadratic classifiers
While QDA is the most commonly used method for obtaining a classifier, other methods are also possible. One such method is to create a longer measurement vector from the old one by adding all pairwise products of individual measurements. For instance, the vector
![[x_1, \; x_2, \; x_3]](/2012-wikipedia_en_all_nopic_01_2012/I/999c70f2ee771cde5b04cf5c4d112852.png)
would become
![[x_1, \; x_2, \; x_3, \; x_1^2, \; x_1x_2, \; x_1 x_3, \; x_2^2, \; x_2x_3, \; x_3^2]](/2012-wikipedia_en_all_nopic_01_2012/I/76486f0e7b54832f55becb8fc8eabceb.png) .
.
Finding a quadratic classifier for the original measurements would then become the same as finding a linear classifier based on the expanded measurement vector. For linear classifiers based only on dot products, these expanded measurements do not have to be actually computed, since the dot product in the higher dimensional space is simply related to that in the original space. This is an example of the so-called kernel trick, which can be applied to linear discriminant analysis, as well as the support vector machine.
References
- Sathyanarayana, Shashi (2010). "Pattern Recognition Primer II". Wolfram Demonstrations Project. http://demonstrations.wolfram.com/PatternRecognitionPrimerII.